3-1 대규모 분산 처리의 프레임워크
구조화 데이터 vs 비 구조화 데이터
구조화 데이터
SQL로 데이터 집계할때 명확히 정해진 스키마가 있음
비구조화 데이터
이미지, 동영상 등 정해진게 없는 데이터
스키마리스 데이터
기본 서식은 있지만 스키마 정의가 안됨
ex) CSV, JSON, XML등
데이터 구조화의 파이프라인

열 지향 스토리지에선 팩트 테이블과 디멘전 테이블로 나뉜다.
팩트 테이블
시간에 따라 증가하는 데이터
디멘전 테이블
그에 따른 부속 데이터
비 구조화 데이터를 열 지향 스토리지로 변환하는 과정
데이터의 가공 및 압축을 위해 많은 컴퓨터 리소스를 사용
분산 처리 프레임워크중 Hadoop과 Spark가 있다.
Hadoop
분산 데이터 처리의 공통 플랫폼
단일 소프트웨어가 아닌 분산 시스템을 구성하는 다수의 소프트웨어로 이루어진 집합체
- 분산 파일 시스템
- 리소스 관리자
- 분산 데이터 처리
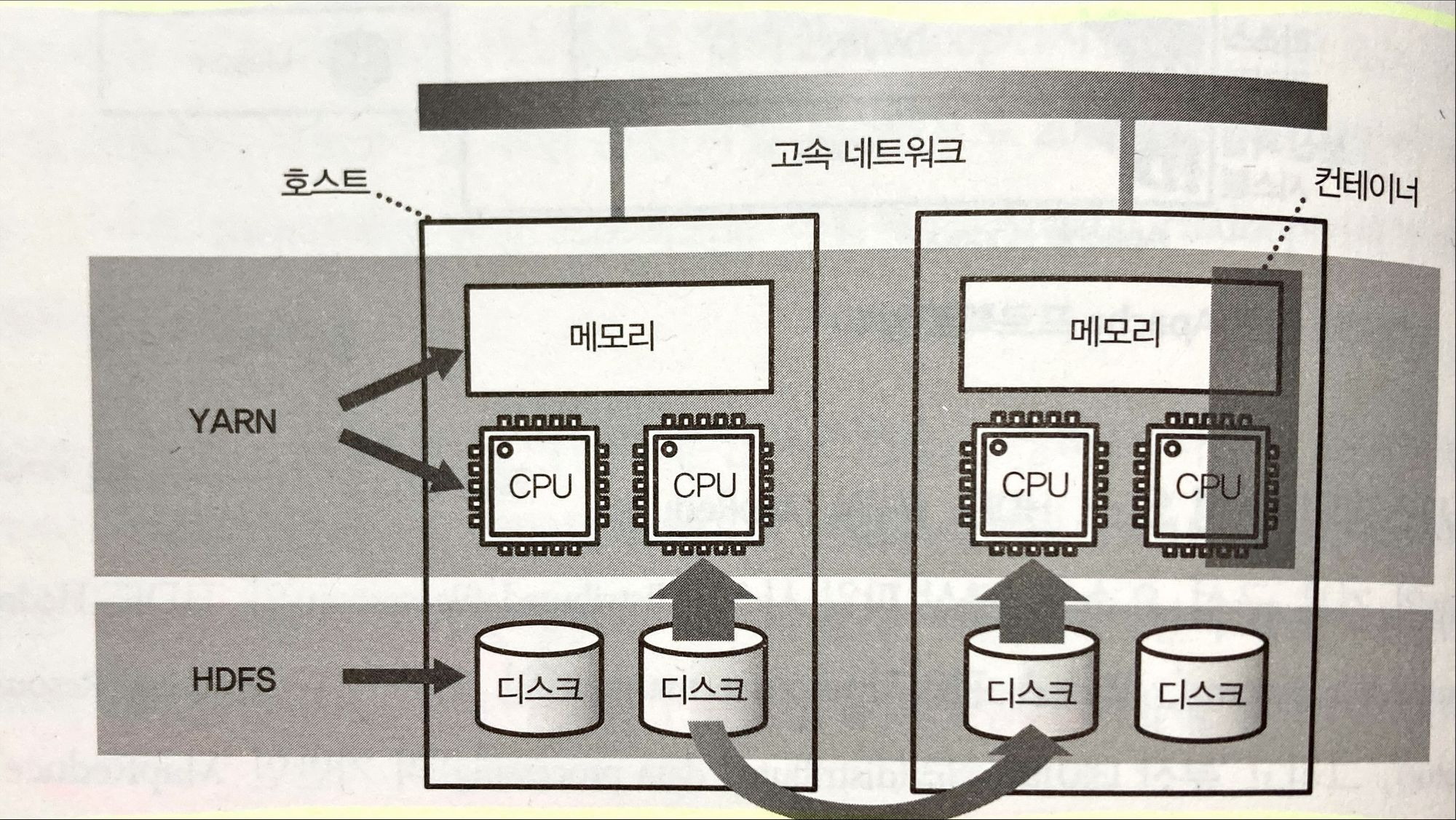
분산 파일 시스템의 역할은 분산 처리 시스템에 필요한 데이터를 저장한다.
리소스 관리자는 CPU코어와 메모리를 관리하고 적절히 조율한다.
이때 관리되는 단위는 컨테이너이다.
컨테이너 어떤 호스트에서 어떤 프로세스를 실행시킬 것인지 결정하는 애플리케이션 수준의 기술
분산 데이터 처리는 여러가지 선택지가 있다.
- MapReduce
- Hive
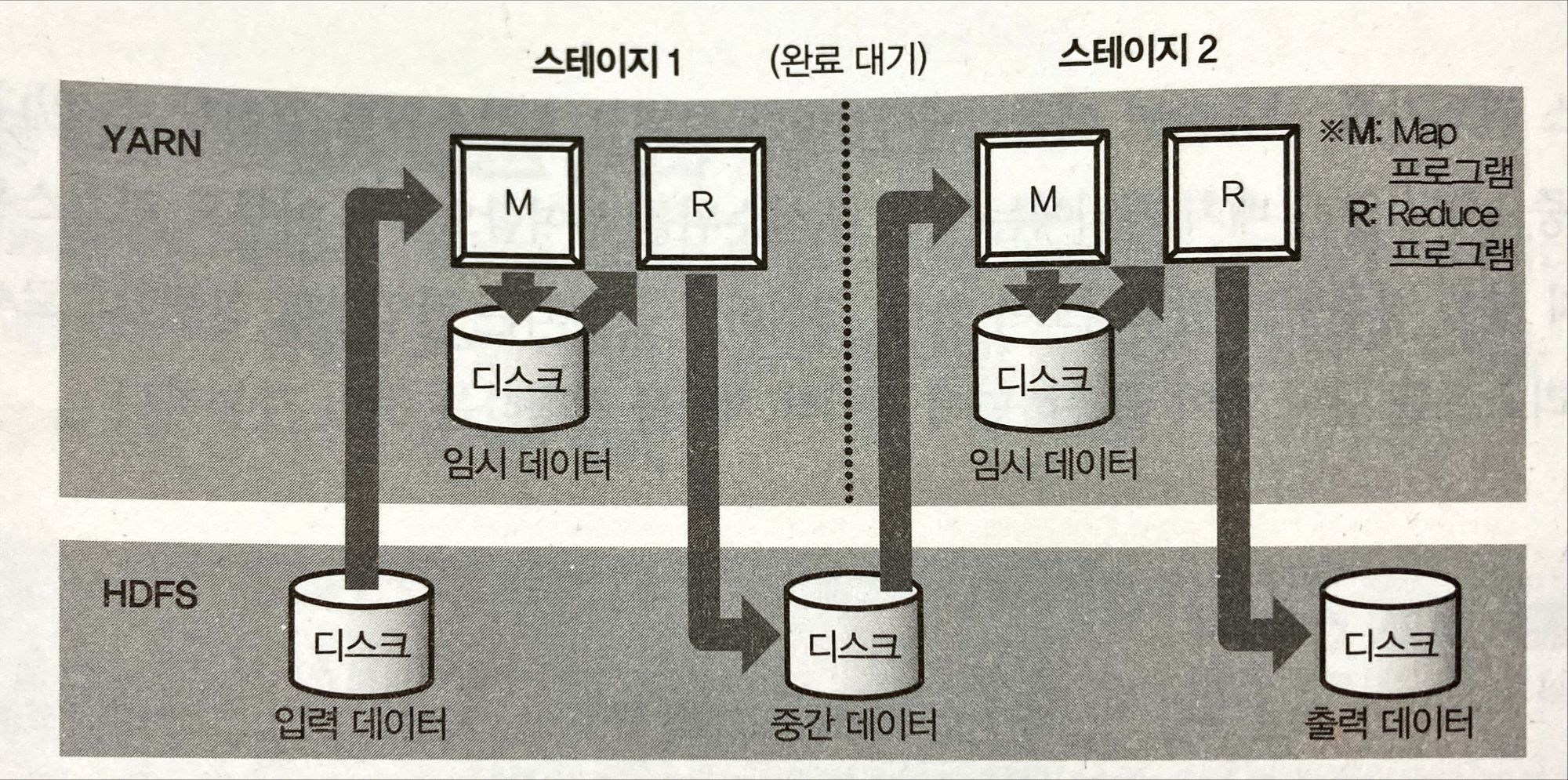
MapReduce는 비구조화 데이터 가공에 좋음
대향의 데이터를 배치 처리하기위한 용도
Hive는 SQL등의 쿼리언어에 의한 집계할때 좋음
MapReduce의 단점을 극복하기 위해 이전 단계가 끝나길 기다리지 않고 바로 다음단계를 실행시킴
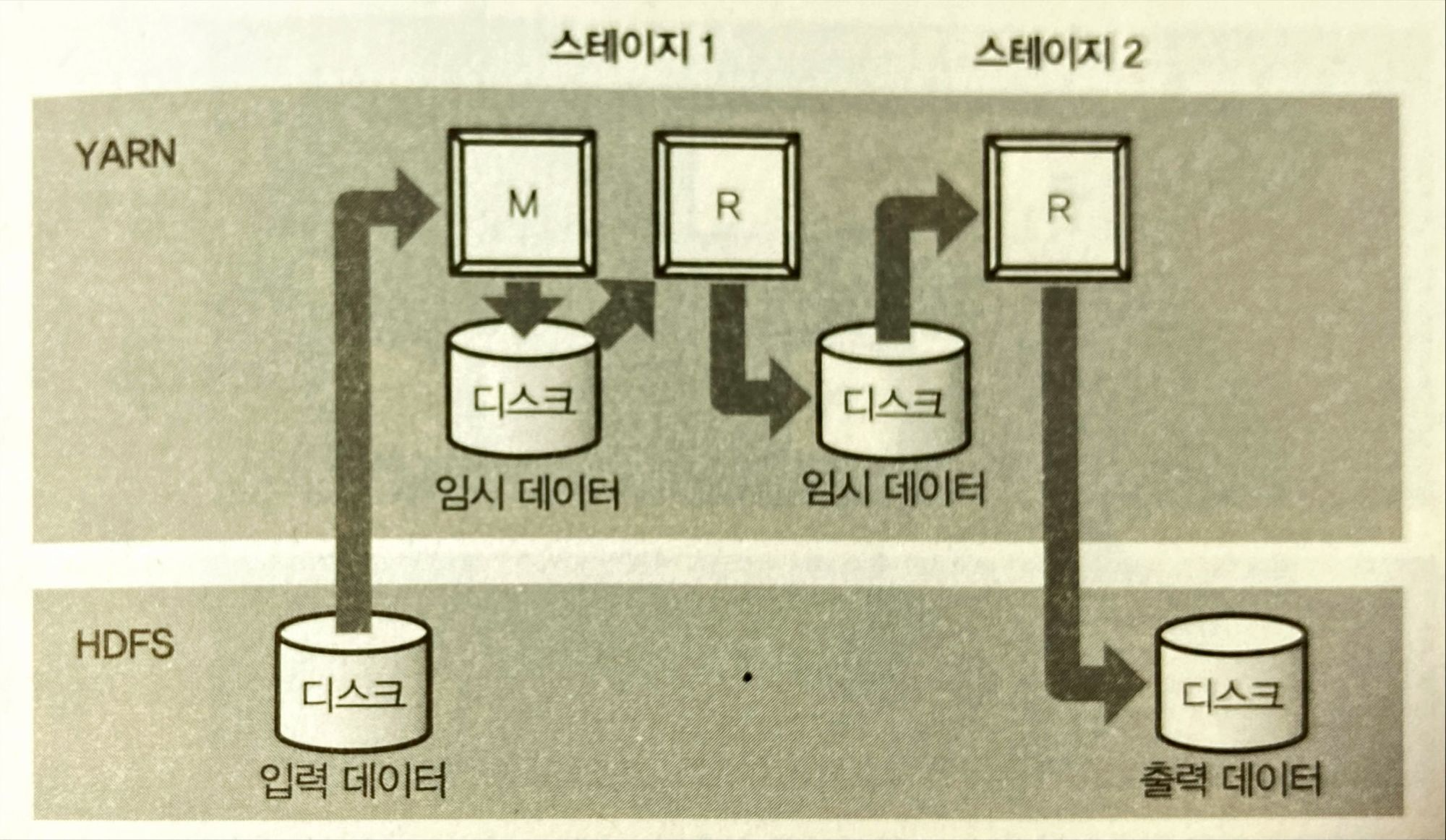
대화형 쿼리 엔진 - Impala & Presto
쿼리 실행을 빠르게 하기위한 쿼리엔진
Spark - 인메모리 형의 고속 데이터 처리
효율적인 데이터 처리를 위한 프로젝트
Hadoop과 독립된 프로젝트
- 대량의 메모리를 활용하여 고속화
- 디스크에 기록하지 않음
- Java 런타임이 필요
- 데이터 처리는 스크립트 언어 사용 가능
중간에 비정상적으로 종료되면 다 날아가서 다시 실행해야함

쿼리 엔진
'개발 > Data' 카테고리의 다른 글
| [빅데이터를 지탱하는 기술] 빅데이터 입문기 #3 (0) | 2020.12.30 |
|---|---|
| [빅데이터를 지탱하는 기술] 빅데이터 입문기 #2 (0) | 2020.12.30 |
| [빅데이터를 지탱하는 기술] 빅데이터 입문기 #1 (0) | 2020.12.30 |